Hidden files in an S3 bucket
Recently, during a routine backup procedure for personal files, I discovered that my private bucket, which should contain only one archive, for some reason has approximately 500 objects in it. This surprised me greatly, and I decided to investigate what the issue was and how it happened.
Prologue #
Backup is a good habit not only for professional projects but also for personal ones. Your hard drive may die of old age, your cat may spill soda on your laptop, or your dog can chew on your flash drive. A transnational megacorporation may decide one day that your promotional "Lifetime Unlimited Photo Storage" package is not actually lifetime and not that unlimited after all. Accidents happen.
As an engineer, I prefer to be safe rather than sorry. That's why I set up backups of my personal data once in a while (and I advise you to do the same). Specifically, I store one copy of my backup archive on a local hard drive, and another copy I upload to relatively cheap AWS S3 storage.
S3 offers a great variety of storage options depending on your needs: it can be very cheap, but with increased retrieval times, or it can be available for instant download but slightly more expensive. There are also different options depending on the chosen class[1].
But I went off track.
Usually, I upload an archive to S3 when the backup is ready and forget about it, but this time something prompted me to click through all the tabs in the bucket view, and I discovered a curious finding.
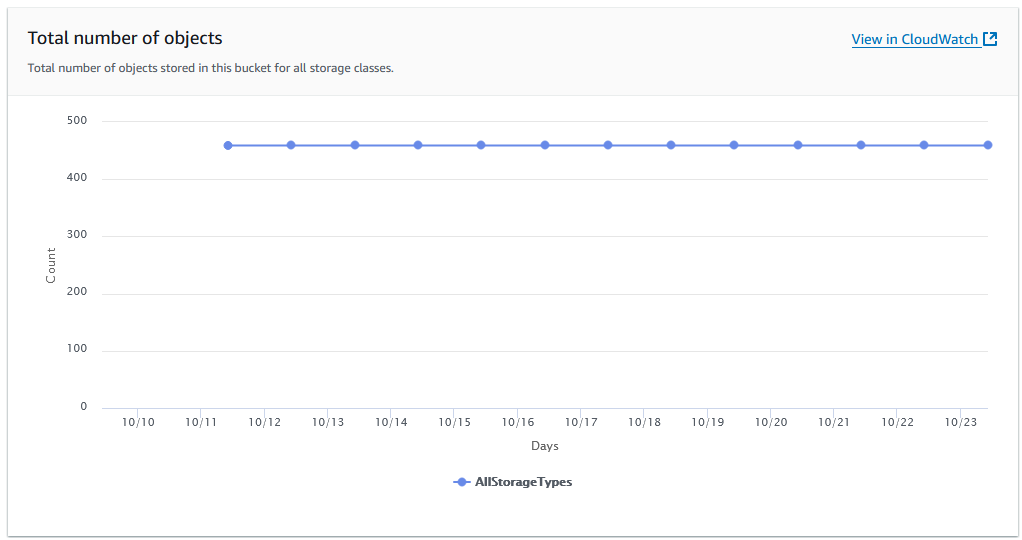
I am 100% sure that my bucket contains only one (1) file. Where did all these files come from?
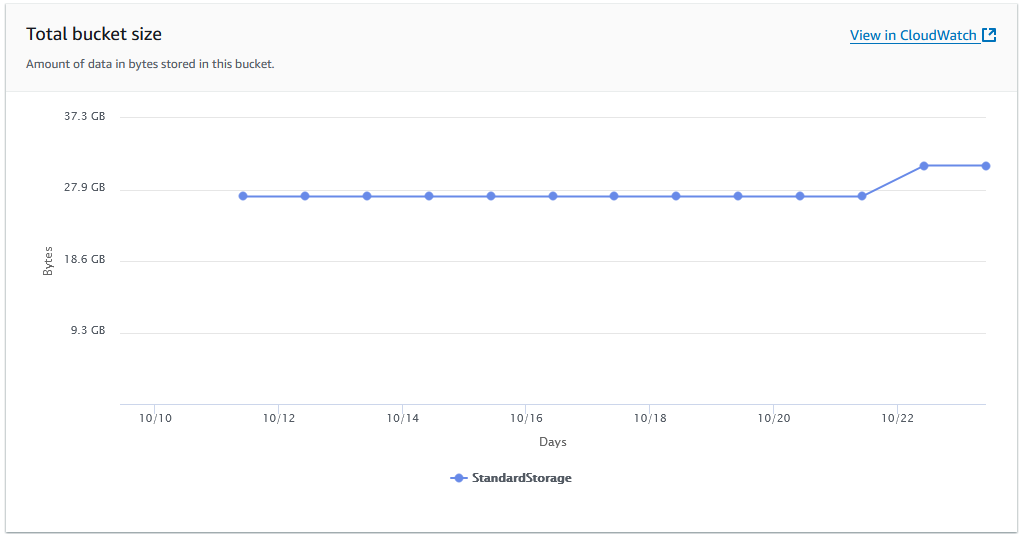
And why does my bucket weigh more than the size of that one object?
Finding Nemo #
Not long ago, there was a story[2] about a feature™ in AWS S3, stating that unauthorized requests to your bucket are still your responsibility to pay for. That was a bummer, to say the least. Remembering that story, my first thought was that someone had figured out the name of my bucket and used it for malicious purposes. (I don't know how it's possible to upload invisible files to someone else's bucket -- but still.) My next idea was that, somehow, I had left the bucket with open permissions. I checked everything, and that wasn't the case; only the publicly available bucket for my static website is open for read access, and that's it.
So why are there invisible files in my S3 bucket? And how do I find them?
I decided to use awscli to look for the objects. The awscli has an s3 ls command, which didn't show any objects except for the one that was actually there. This started to annoy me. I prepared a final solution for the situation: recreate the bucket, re-upload the archive, and forget about it. But my lack of understanding regarding the root cause behind this situation annoyed me even more. So I decided to push a little further.
What other options did I have? I frequently use the boto3 library, so I decided to give it a go.
The library has several "list" actions as well, and I started with the most plausible ones. Unfortunately, simple list_buckets, list_directory_buckets, list_object_versions, list_objects, and list_objects_v2 showed me nothing. However, there were a few less straightforward actions: list_multipart_uploads and list_parts.
python$ python3
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import boto3
>>> response = s3.list_multipart_uploads(Bucket="my-cool-bucket")
>>> print(response)
{'ResponseMetadata': {'RequestId': '[REDACTED]', 'HostId': '[REDACTED]', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': '[REDACTED]', 'x-amz-request-id': '[REDACTED]', 'date': 'Fri, 25 Oct 2024 10:10:42 GMT', 'content-type': 'application/xml', 'transfer-encoding': 'chunked', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Bucket': 'my-cool-bucket', 'KeyMarker': '', 'UploadIdMarker': '', 'NextKeyMarker': 'archive_2023.tar.gz', 'NextUploadIdMarker': '[REDACTED]', 'MaxUploads': 1000, 'IsTruncated': False, 'Uploads': [{'UploadId': '[REDACTED]', 'Key': 'archive_2023.tar.gz', 'Initiated': datetime.datetime(2023, 12, 21, 12, 1, 22, tzinfo=tzutc()), 'StorageClass': 'STANDARD', 'Owner': {'DisplayName': 'hatedabamboo', 'ID': '[REDACTED]'}, 'Initiator': {'ID': '[REDACTED]', 'DisplayName': 'hatedabamboo'}}]}
Well, well, well, what do we have here! A strange multipart upload that was created almost a year ago. Actually, "strange" isn't the right word -- it was definitely me who started it, though I have no memory of it whatsoever. And it seems it was never completed.
From this response, we can try to dig up even more information.
python>>> response = s3.list_parts(Bucket="my-cool-bucket", Key="archive_2023.tar.gz", UploadId="[REDACTED]")
>>> print(response["Parts"])
[{'PartNumber': 1, 'LastModified': datetime.datetime(2023, 12, 21, 12, 1, 26, tzinfo=tzutc()), 'ETag': '"[REDACTED]"', 'Size': 17179870}, {'PartNumber': 2, 'LastModified': datetime.datetime(2023, 12, 21, 12, 1, 32, tzinfo=tzutc()), 'ETag': '"[REDACTED]"', 'Size': 17179870}, {'PartNumber': 3, 'LastModified': datetime.datetime(2023, 12, 21, 12, 1, 38, tzinfo=tzutc()), 'ETag': '"[REDACTED]"', 'Size': 17179870}, {'PartNumber': 4, ... (and many, many more)
>>> print(len(response["Parts"]))
457
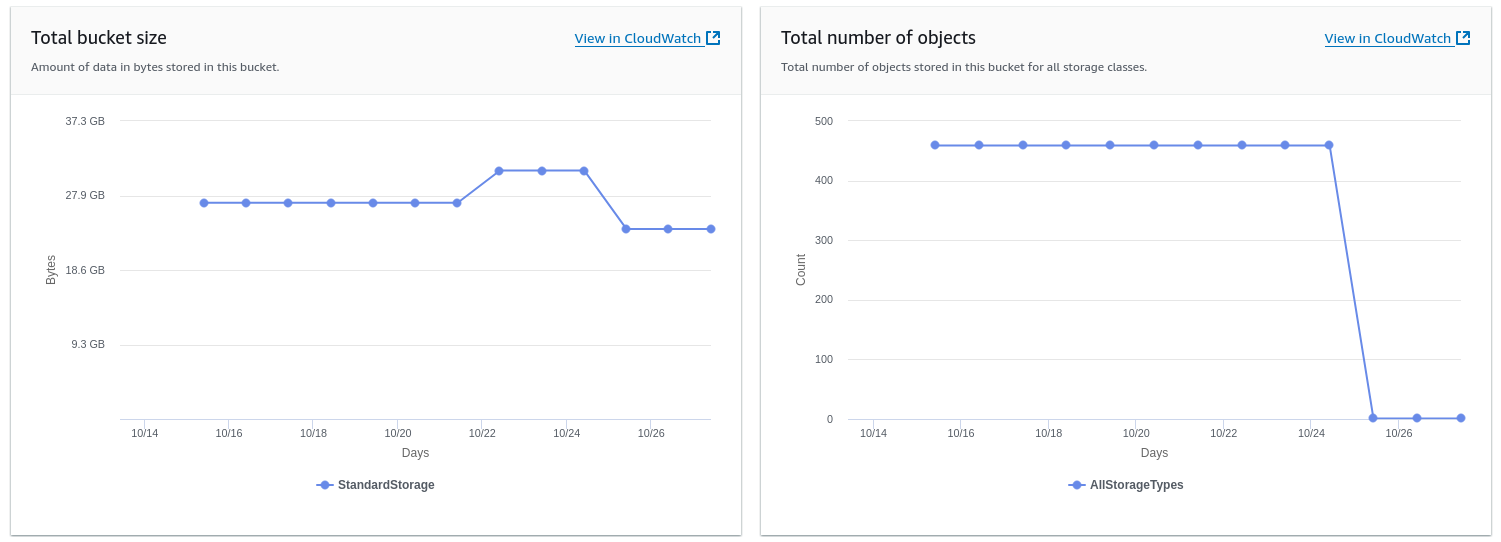
And there they are -- all these unknown, hidden, invisible objects in my bucket with just a single file. It took a while to notice the issue and see the updated metrics. Deleting the parts themselves was a piece of cake.
python>>> response = s3.abort_multipart_upload(Bucket="my-cool-bucket", Key="archive_2023.tar.gz", UploadId="[REDACTED]")
>>> print(response)
{'ResponseMetadata': {'RequestId': '[REDACTED]', 'HostId': '[REDACTED]', 'HTTPStatusCode': 204, 'HTTPHeaders': {'x-amz-id-2': '[REDACTED]', 'x-amz-request-id': '[REDACTED]', 'date': 'Fri, 25 Oct 2024 10:22:35 GMT', 'server': 'AmazonS3'}, 'RetryAttempts': 0}}
>>> response = s3.list_multipart_uploads(Bucket="my-cool-bucket")
>>> print(response)
{'ResponseMetadata': {'RequestId': '[REDACTED]', 'HostId': '[REDACTED]', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': '[REDACTED]', 'x-amz-request-id': '[REDACTED]', 'date': 'Fri, 25 Oct 2024 10:23:39 GMT', 'content-type': 'application/xml', 'transfer-encoding': 'chunked', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Bucket': 'my-cool-bucket', 'KeyMarker': '', 'UploadIdMarker': '', 'NextKeyMarker': '', 'NextUploadIdMarker': '', 'MaxUploads': 1000, 'IsTruncated': False}
Poof! The multipart upload, along with all its parts, is now gone for good.
Afterthought #
So what happened, after all?
It seems that once, when uploading a file via the AWS Web Console, I opted for a multipart upload, which seemed like a faster solution. Was it faster? I don't remember. But apparently, somewhere during the process, the upload failed, and I had to restart from scratch. Yet, the existing multipart upload stayed there -- unnoticed, untouched, with all its parts just waiting to be removed.
This is a very counterintuitive experience for anyone using the Web Console, as there's no way to locate failed multipart uploads or view their progress or parts if you didn't initiate the upload or closed the original window. Even a simple internet interruption could cause the upload to fail, leaving orphaned parts behind.
Multipart upload is a nice feature, but it lacks visibility for users, and that's a major downside. In the end, it's your money on the table. I can easily imagine situations where people don't closely monitor the number of files in their buckets or the total size, leaving dead multipart uploads lying around, silently draining your budget cent by cent.
Closing remarks
As always, feel free to disagree with me, correct my mistakes and befriend me on one of the social media platforms listed below.